Studi Kasus, Web Server Cloud Down Intermiten dengan Load Normal tapi Response Lambat
Tiket masuk dari tim customer support. “Website kadang bisa, kadang tidak. Sudah 3 hari seperti ini.”
Di artikel ini, kita membahas webserver cloud down intermiten secara praktis agar kamu paham konteks dan penerapannya.
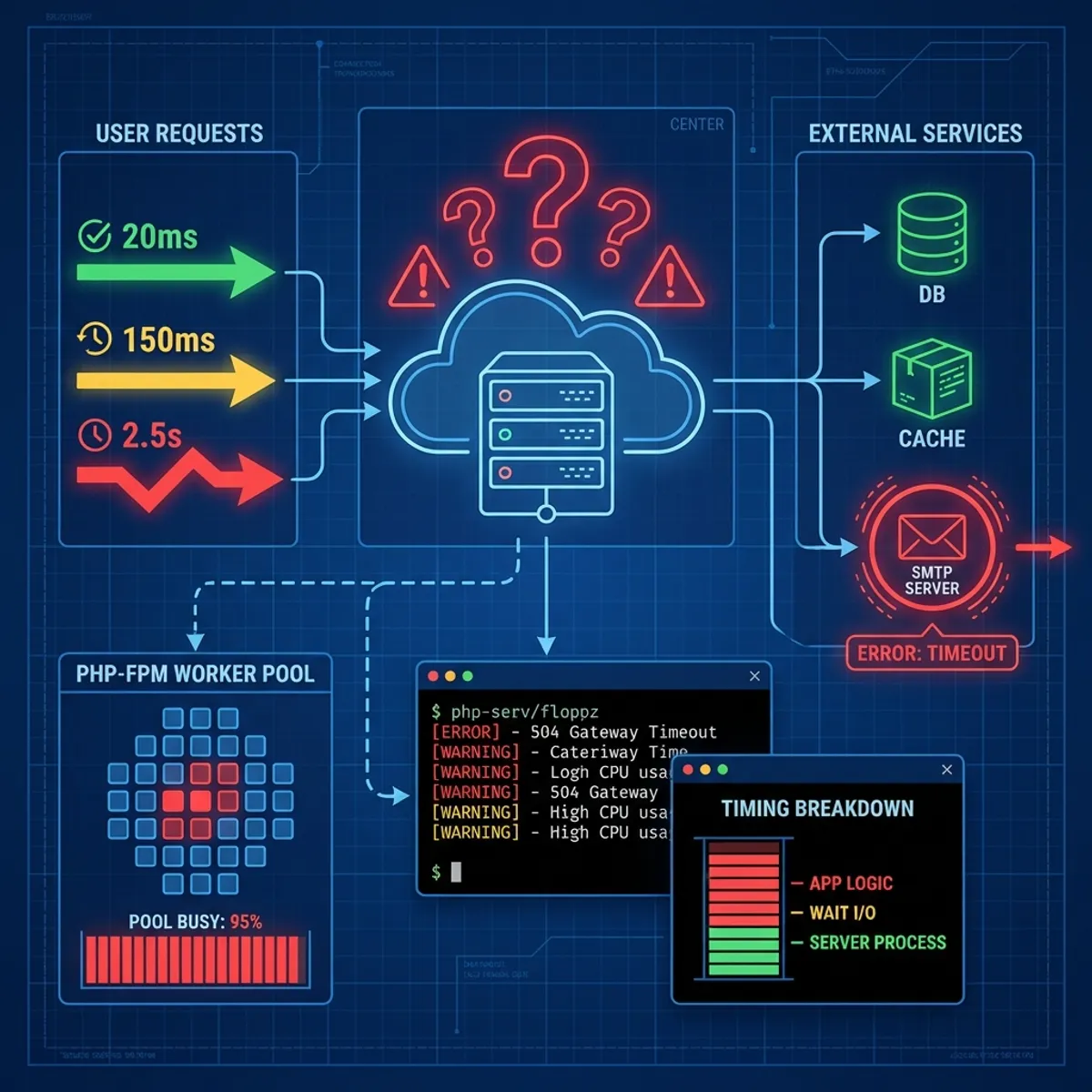
Saya buka monitoring. CPU usage 20%. Memory usage 40%. Disk I/O normal. Load average 0.5 di server dengan 4 core. Semua terlihat baik baik saja.
Tapi ketika saya coba akses website dari browser, butuh 15 detik untuk loading halaman pertama. Kadang timeout. Kadang normal. Pola yang tidak konsisten.
“Ini pasti menarik,” pikir saya. Dan memang, kasus ini mengajarkan saya banyak hal tentang debugging yang tidak terlihat di metrics standar.
Kronologi masalah
Client ini menjalankan aplikasi e-commerce berbasis Laravel di DigitalOcean droplet. Arsitekturnya sederhana.
- 1 Droplet untuk web server (Nginx + PHP-FPM)
- 1 Managed Database (MySQL)
- Cloudflare sebagai CDN dan DNS
Aplikasi sudah berjalan lancar selama 8 bulan. Tidak ada perubahan konfigurasi dalam 2 minggu terakhir. Deploy terakhir adalah minor bug fix 5 hari lalu.
Tiba tiba, user mulai komplain. Checkout lambat. Halaman produk tidak mau loading. Tapi tidak selalu. Kadang normal, kadang bermasalah.
Gejala yang diamati
Dari observasi awal, ini pattern yang saya temukan.
- Response time bervariasi dari 200ms hingga 30 detik
- Tidak ada korelasi dengan waktu tertentu (pagi, siang, malam sama saja)
- Beberapa request timeout dengan status 504 (Gateway Timeout)
- Metrics server (CPU, memory, disk) selalu terlihat normal
- Database query time juga normal (di bawah 100ms rata rata)
“Kalau bukan server, bukan database, lalu apa?” Pertanyaan ini terus berputar di kepala saya.
Proses investigasi
Saya mulai dengan pendekatan sistematis. Layer by layer.
Step 1: cek dari perspektif user
Sebelum masuk ke server, saya test dari sisi user dulu.
curl -w "@curl-format.txt" -o /dev/null -s https://example.com/Dengan format file yang menampilkan breakdown waktu.
time_namelookup: %{time_namelookup}\n
time_connect: %{time_connect}\n
time_appconnect: %{time_appconnect}\n
time_pretransfer: %{time_pretransfer}\n
time_redirect: %{time_redirect}\n
time_starttransfer: %{time_starttransfer}\n
time_total: %{time_total}\nHasilnya mengejutkan.
time_namelookup: 0.012
time_connect: 0.150
time_appconnect: 0.350
time_pretransfer: 0.350
time_starttransfer: 12.543
time_total: 12.890DNS lookup dan TCP connect cepat. Tapi time_starttransfer (waktu sampai byte pertama diterima) sangat lama. Ini berarti masalah ada di processing server, bukan network.
Step 2: cek NGINX access log
Masuk ke server, saya analisis access log.
tail -f /var/log/nginx/access.log | awk '{print $NF}'Kolom terakhir di log Nginx biasanya adalah request time. Saya melihat banyak request dengan waktu di atas 10 detik. Tapi yang aneh, tidak semua. Ada yang 0.1 detik, ada yang 15 detik.
Step 3: cek php-fpm status
Karena ini aplikasi PHP, saya cek status PHP-FPM.
curl http://127.0.0.1/status?fullOutput menunjukkan sesuatu yang menarik.
active processes: 30
idle processes: 0
listen queue: 45
max listen queue: 128Semua 30 proses PHP-FPM aktif. Tidak ada yang idle. Dan ada 45 request menunggu di queue.
“Ini dia,” pikir saya. PHP-FPM kehabisan worker. Tapi kenapa? Load tidak tinggi.
Step 4: identifikasi proses yang lama
Saya perlu tahu apa yang membuat PHP-FPM busy.
ps aux | grep php-fpm | awk '{print $2}' | xargs -I {} strace -p {} -cSetelah beberapa menit observasi, saya melihat banyak waktu dihabiskan di connect() dan poll(). System call yang biasanya terkait dengan network connection.
Step 5: cek connection ke external services
Aplikasi Laravel ini ternyata connect ke beberapa external services.
- Payment gateway
- Email SMTP
- Third party analytics
Saya coba curl ke masing masing endpoint.
time curl https://payment-gateway.example/api/healthPayment gateway response 200ms. Normal.
time curl https://smtp.mailprovider.com:587Timeout setelah 30 detik.
Bingo.
Root cause teridentifikasi
Ternyata mail provider yang digunakan mengalami masalah di region Asia. Setiap kali ada trigger untuk mengirim email (order confirmation, password reset, notification), PHP-FPM worker stuck menunggu connection ke SMTP server.
Karena email sending dilakukan synchronously (bukan via job queue), setiap request yang trigger email akan memakan satu PHP-FPM worker sampai timeout.
Dengan 30 worker dan rata rata 10 request per detik yang trigger email, worker cepat habis. Request lain harus antri.
Ini menjelaskan kenapa.
- Metrics server normal (worker stuck di I/O wait, bukan CPU)
- Response intermiten (hanya request yang trigger email yang lambat)
- Tidak ada pattern waktu (tergantung user action, bukan traffic volume)
Solusi yang diterapkan
Solusi immediate: disable email temporarily
Langkah pertama untuk recovery adalah mematikan email sending sementara.
Di Laravel, saya ubah konfigurasi.
// config/mail.php
'default' => env('MAIL_MAILER', 'log'),Dengan mengalihkan ke log, semua email akan ditulis ke log file instead of dikirim. Website langsung responsif kembali.
Solusi jangka pendek: queue email sending
Email seharusnya tidak dikirim synchronously. Ini best practice yang sering diabaikan.
// Instead of
Mail::to($user)->send(new OrderConfirmation($order));
// Use
Mail::to($user)->queue(new OrderConfirmation($order));Setup queue worker untuk process email di background.
php artisan queue:work --queue=emailsSekarang, meskipun SMTP server lambat, website tetap responsif karena email diproses asynchronously.
Solusi jangka panjang: timeout dan fallback
Tambahkan timeout yang masuk akal untuk semua external connection.
// config/mail.php
'smtp' => [
'timeout' => 5, // 5 seconds max
],Dan setup fallback. Kalau primary mail provider gagal, gunakan secondary.
try {
Mail::mailer('primary')->to($user)->send($notification);
} catch (\Exception $e) {
Log::warning('Primary mail failed, using fallback');
Mail::mailer('fallback')->to($user)->send($notification);
}Solusi monitoring: alert untuk queue length
Tambahkan monitoring untuk PHP-FPM queue dan external service health.
Di Prometheus, saya buat alert.
- alert: PHPFPMQueueHigh
expr: phpfpm_listen_queue > 10
for: 2m
annotations:
summary: "PHP-FPM queue is backing up"Dengan ini, masalah serupa akan terdeteksi lebih awal.
Untuk monitoring yang lebih comprehensive, saya sudah menulis tentang pentingnya monitoring dan cara memilih tools.
Pelajaran dari kasus ini
External dependencies adalah risk
Setiap kali aplikasi kamu bergantung pada external service (API pihak ketiga, SMTP, payment gateway), ada potensi failure. Dan failure itu bisa cascade ke seluruh sistem.
Mitigasi:
- Timeout yang reasonable untuk semua external calls
- Circuit breaker pattern untuk auto-disable service yang bermasalah
- Async processing untuk operasi yang tidak perlu immediate response
Metrics standar tidak cukup
CPU, memory, disk. Metrics ini penting, tapi tidak menunjukkan gambaran lengkap. PHP-FPM worker stuck di I/O tidak menciptakan CPU spike. Tapi tetap menyebabkan downtime.
Mitigasi:
- Monitor application level metrics (queue length, response time distribution)
- Monitor external service health dari perspektif aplikasi kamu
Synchronous adalah anti pattern untuk external calls
Ini lesson yang harus dipelajari semua developer. Jangan pernah melakukan blocking call ke external service di main request cycle.
Mitigasi:
- Gunakan job queue (Redis, RabbitMQ, database queue)
- Fire and forget jika response tidak diperlukan
- Webhook atau callback jika butuh response asynchronous
Documentation membantu debugging
Saya bisa menemukan masalah lebih cepat karena ada dokumentasi tentang external services apa saja yang digunakan aplikasi ini. Bayangkan kalau saya harus menelusuri kode untuk mencari semua external calls.
Checklist debugging response lambat
Berdasarkan pengalaman ini, saya buat checklist yang bisa digunakan untuk kasus serupa.
- Verify dari perspektif user menggunakan curl dengan timing breakdown
- Cek application server logs untuk pattern waktu response
- Cek worker pool status (PHP-FPM, Puma, Gunicorn, dll)
- Identifikasi blocking operations menggunakan strace atau profiler
- Test connectivity ke semua external services satu per satu
- Review recent changes meskipun terlihat tidak relevan
- Check for resource exhaustion yang tidak terlihat di basic metrics (file descriptors, connection pool, worker count)
Penutup
Debugging adalah seni. Kadang masalah terlihat jelas dari metrics. Kadang tersembunyi di tempat yang tidak kamu expect.
Server dengan load 0.5 bisa saja tidak responsif. CPU 20% tidak berarti semuanya baik baik saja. Angka angka itu perlu konteks.
Yang membedakan engineer berpengalaman bukan tools yang dipakai, tapi kemampuan untuk berpikir sistematis. Layer by layer. Eliminate possibilities satu per satu.
Dan selalu, selalu, perhatikan external dependencies. Karena seringkali, musuh terbesar bukan dari dalam, tapi dari luar.
Semoga pembahasan webserver cloud down intermiten ini membantu kamu mengambil keputusan yang lebih tepat di lapangan.
Checklist Implementasi
- Uji langkah di lab terlebih dulu sebelum produksi.
- Dokumentasikan konfigurasi, versi, dan langkah rollback.
- Aktifkan monitoring + alert untuk komponen yang diubah.
- Audit akses dan terapkan prinsip least privilege.
Referensi Resmi
Butuh Bantuan?
Jika ingin implementasi aman di produksi, saya bisa bantu assessment, eksekusi, dan hardening.
Hubungi SayaTentang Penulis
Kamandanu Wijaya
IT Infrastructure & Network Administrator
Administrator infrastruktur & jaringan dengan pengalaman enterprise 14+ tahun, fokus stabilitas, keamanan, dan automasi.
Sertifikasi: Google IT Support, Cisco Networking Academy, DevOps.
Lihat ProfilButuh Solusi IT?
Tim DoWithSudo siap membantu setup server, VPS, dan sistem keamanan lo.
Hubungi Kami