Seberapa Penting Monitoring dan Bagaimana Memilih Tools yang Tepat
“Kenapa website down?”
Di artikel ini, kita membahas monitoring infrastruktur secara praktis agar kamu paham konteks dan penerapannya.
Pertanyaan itu datang dari Client. Langsung ke grup WhatsApp tim saya. Pukul 3 sore di hari minggu.
Saya buka laptop, cek server. Semuanya terlihat normal. Website bisa diakses dari jaringan vpn. Tapi dari luar? Tidak bisa.
Butuh 2 jam untuk menemukan masalahnya. Ternyata salah satu node di load balancer mengalami memory leak dan berhenti merespons. Tapi karena tidak ada monitoring yang proper, tidak ada alert. Tidak ada notifikasi. Kami baru tahu setelah customer komplain.
Pengalaman itu mengubah cara saya memandang monitoring. Dari “nice to have” menjadi “absolutely critical”.
Mengapa monitoring sering diabaikan
Banyak tim IT, terutama yang kecil, menganggap monitoring sebagai sesuatu yang bisa ditunda. Alasannya bermacam macam.
“Server masih baru, belum perlu monitoring.”
“Kita bisa cek manual kalau ada masalah.”
“Setup monitoring itu ribet dan makan waktu.”
Saya pernah berpikir seperti itu juga. Sampai kejadian di atas menyadarkan saya.
Realita di lapangan
Tanpa monitoring, kamu hanya bereaksi. Bukan proaktif.
Bayangkan kamu punya mobil tanpa dashboard. Tidak ada speedometer, tidak ada indikator bensin, tidak ada lampu peringatan mesin. Kamu tetap bisa menyetir, tapi kamu tidak akan tahu ada masalah sampai mobil mogok di tengah jalan.
Server tanpa monitoring persis seperti itu.
Ketika disk hampir penuh, kamu tidak tahu. Ketika memory usage naik drastis, kamu tidak tahu. Ketika ada spike traffic yang tidak biasa, kamu tidak tahu.
Sampai semuanya crash.
Apa yang harus dimonitor
Sebelum bicara tools, mari kita tentukan dulu apa yang perlu dipantau.
Infrastructure metrics
Ini adalah dasar dari semua monitoring.
- CPU usage: Apakah server bekerja terlalu keras?
- Memory usage: Apakah ada memory leak?
- Disk usage: Apakah storage hampir penuh?
- Network I/O: Apakah ada bottleneck bandwidth?
- Load average: Apakah sistem overwhelmed?
Application metrics
Selain infrastruktur, aplikasi juga perlu dipantau.
- Response time: Berapa lama request diproses?
- Error rate: Berapa persen request yang gagal?
- Request per second: Berapa banyak traffic yang masuk?
- Database query time: Apakah ada query yang lambat?
Business metrics
Ini sering dilupakan, padahal sangat penting.
- Active users: Berapa user yang sedang menggunakan sistem?
- Transaction volume: Berapa transaksi per jam?
- Conversion rate: Apakah ada anomali di funnel?
Log aggregation
Metrics saja tidak cukup. Kamu juga butuh log untuk debugging.
- Application logs: Error messages, stack traces
- Access logs: Siapa mengakses apa
- Security logs: Failed login attempts, suspicious activities
Perbandingan tools monitoring populer
Ada banyak pilihan di pasaran. Ini beberapa yang sering saya gunakan.
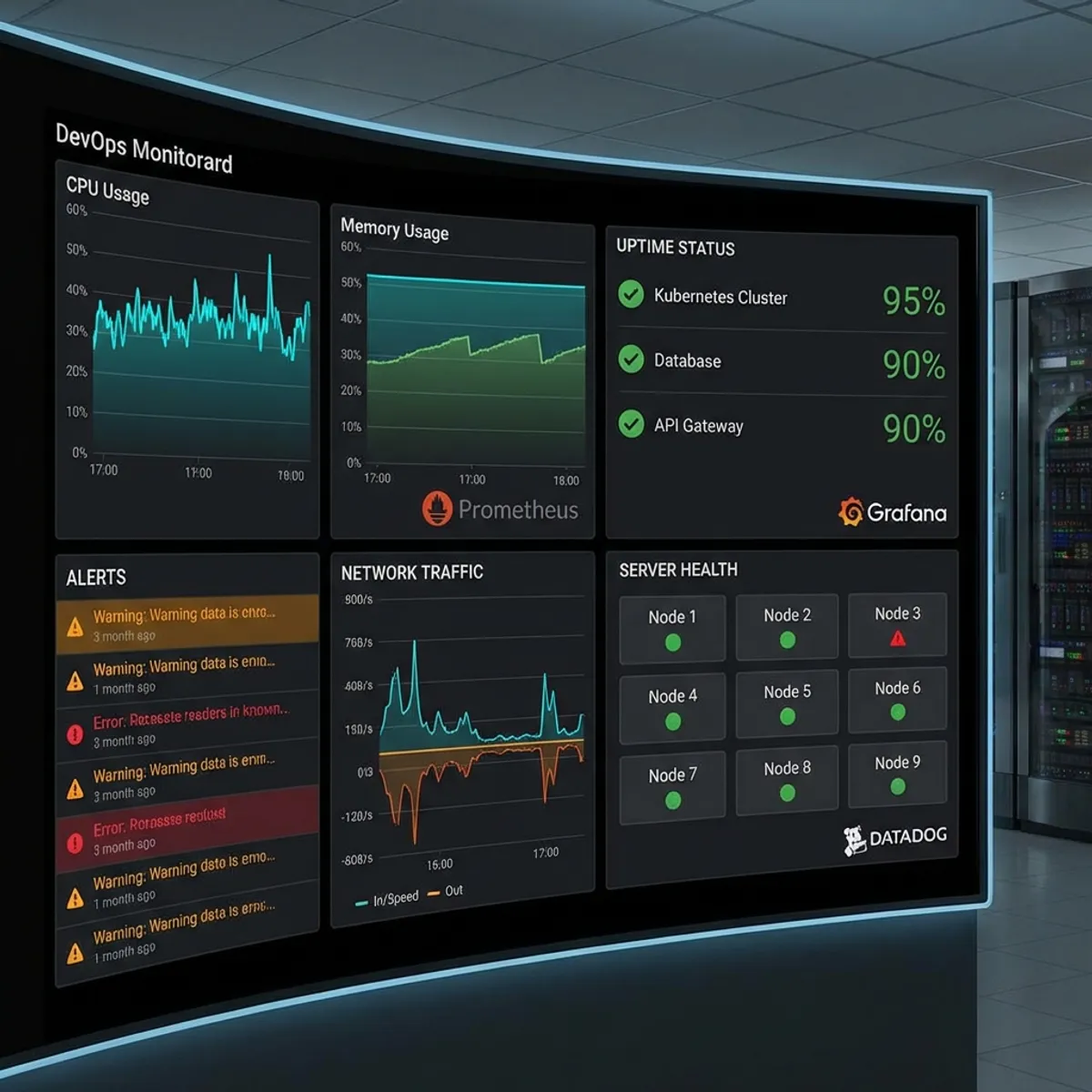
Prometheus + Grafana
Kombinasi paling populer untuk monitoring open source.
Kelebihan:
- Gratis dan open source
- Pull based model yang fleksibel
- Query language (PromQL) yang powerful
- Ekosistem exporter yang luas
- Grafana dashboard yang cantik
Kekurangan:
- Setup awal bisa kompleks
- Butuh storage yang cukup untuk time series data
- Tidak ada built in alerting UI yang bagus (butuh Alertmanager)
Cocok untuk: Tim yang punya resource untuk setup dan maintain sendiri.
Datadog
Platform monitoring komersial yang sangat lengkap.
Kelebihan:
- Setup sangat mudah
- UI yang intuitif
- APM, logs, dan metrics dalam satu platform
- Integrasi dengan ratusan services
- Support yang responsif
Kekurangan:
- Mahal, terutama untuk infrastruktur besar
- Vendor lock in
- Pricing bisa membingungkan
Cocok untuk: Perusahaan dengan budget dan butuh solusi cepat.
Zabbix
Veteran di dunia monitoring, sudah ada sejak 2001.
Kelebihan:
- Gratis dan open source
- Fitur sangat lengkap
- Auto discovery yang bagus
- Bisa monitoring hampir semua jenis device
Kekurangan:
- UI terasa outdated
- Learning curve cukup tinggi
- Dokumentasi kadang membingungkan
Cocok untuk: Organisasi yang butuh monitoring traditional infrastructure.
Uptime kuma
Solusi ringan untuk uptime monitoring.
Kelebihan:
- Setup sangat mudah (satu container Docker)
- UI modern dan bersih
- Notifikasi ke banyak channel
- Self hosted, gratis selamanya
Kekurangan:
- Fokus hanya pada uptime, bukan metrics detail
- Tidak ada APM atau log aggregation
Cocok untuk: Monitoring endpoint sederhana, cocok untuk startup atau proyek personal.
Netdata
Real time monitoring dengan visualisasi yang menarik.
Kelebihan:
- Instalasi satu perintah
- Dashboard real time yang detail
- Ringan, tidak banyak overhead
- Gratis untuk penggunaan dasar
Kekurangan:
- Alert configuration tidak se-fleksibel Prometheus
- Cloud version berbayar untuk fitur lengkap
Cocok untuk: Quick setup untuk melihat apa yang terjadi di server.
Bagaimana memilih yang tepat
Tidak ada solusi one size fits all. Pemilihan tergantung beberapa faktor.
Pertimbangkan budget
Kalau budget terbatas, Prometheus + Grafana adalah pilihan solid. Investasi ada di waktu setup dan learning curve.
Kalau budget tersedia dan butuh cepat running, Datadog atau solusi SaaS lainnya lebih masuk akal.
Pertimbangkan skill tim
Tools open source butuh expertise untuk setup dan maintain. Kalau tim tidak punya bandwidth untuk itu, SaaS solution lebih praktis.
Pertimbangkan skala
Untuk infrastruktur kecil (kurang dari 10 server), Uptime Kuma atau Netdata sudah cukup untuk awal.
Untuk infrastruktur menengah hingga besar, Prometheus + Grafana atau Zabbix lebih appropriate.
Pertimbangkan kebutuhan spesifik
Butuh APM? Datadog atau Jaeger.
Butuh log aggregation? ELK Stack atau Loki.
Butuh network monitoring? Zabbix atau PRTG.
Setup minimal yang saya rekomendasikan
Untuk startup atau proyek kecil, ini setup minimal yang saya sarankan.
Level 1: uptime monitoring
Mulai dengan yang paling basic. Kamu harus tahu kalau website atau API down.
# docker-compose.yml untuk Uptime Kuma
version: '3.8'
services:
uptime-kuma:
image: louislam/uptime-kuma
ports:
- "3001:3001"
volumes:
- uptime-kuma-data:/app/data
restart: unless-stopped
volumes:
uptime-kuma-data:Setup monitor untuk setiap endpoint penting. Aktifkan notifikasi ke Telegram, Slack, atau email.
Level 2: server metrics
Setelah uptime, pantau kesehatan server.
Netdata bisa diinstall dalam satu perintah.
bash <(curl -Ss https://my-netdata.io/kickstart.sh)Atau kalau mau lebih proper, setup Prometheus dengan node_exporter.
Level 3: application metrics
Instrument aplikasi kamu untuk expose metrics.
Untuk Node.js, pakai prom-client.
const client = require('prom-client');
const httpRequestDuration = new client.Histogram({
name: 'http_request_duration_seconds',
help: 'Duration of HTTP requests in seconds',
labelNames: ['method', 'route', 'status']
});Level 4: log aggregation
Centralkan semua log ke satu tempat.
Loki + Grafana adalah kombinasi ringan yang bagus untuk ini.
Anti pattern yang sering saya temui
Selama bertahun tahun, saya melihat beberapa kesalahan umum dalam implementasi monitoring.
Alert fatigue
Terlalu banyak alert membuat orang mengabaikannya. Kalau setiap 5 menit ada notifikasi, tidak ada yang direspons.
Solusi: Alert hanya untuk hal yang actionable. CPU usage 80% mungkin tidak perlu alert. CPU usage 95% selama 5 menit? Perlu.
Tidak ada baseline
Bagaimana kamu tahu sesuatu tidak normal kalau tidak tahu apa yang normal?
Solusi: Collect data dulu selama beberapa minggu sebelum setting threshold. Pahami pattern normal.
Monitoring tanpa runbook
Alert berbunyi, lalu apa? Kalau tidak ada dokumentasi tentang apa yang harus dilakukan, alert tidak berguna.
Solusi: Setiap alert harus punya runbook. Langkah langkah untuk investigate dan resolve.
Single point of monitoring
Monitoring server di server yang sama dengan aplikasi. Kalau server itu mati, monitoring juga mati.
Solusi: Monitoring harus terpisah dari yang dimonitor. Idealnya di mesin atau bahkan cloud provider berbeda.
Untuk memastikan server yang dimonitor juga aman, pastikan kamu sudah menerapkan best practice hardening Linux.
Evolusi monitoring di tim saya
Saya ingin berbagi bagaimana monitoring di tim saya berkembang seiring waktu.
Tahun 1: Tidak ada monitoring. Manual check via SSH.
Tahun 2: Basic uptime monitoring dengan Pingdom (versi gratis).
Tahun 3: Self hosted Uptime Kuma + Netdata di setiap server.
Tahun 4: Prometheus + Grafana untuk metrics. Loki untuk logs.
Tahun 5: Full observability stack dengan tracing (Jaeger), APM, dan custom dashboards.
Tidak perlu langsung ke level 5. Mulai dari yang sederhana, iterasi seiring kebutuhan berkembang.
Pelajaran yang saya petik
Pertama, monitoring bukan expense, tapi investment. Waktu yang dihabiskan untuk setup monitoring akan terbayar berkali kali lipat saat incident terjadi.
Kedua, start simple. Jangan mencoba setup stack monitoring kompleks di hari pertama. Mulai dari uptime, lalu expand.
Ketiga, monitoring tanpa response plan tidak berguna. Alert harus diikuti dengan action yang jelas.
Keempat, review dan refine secara berkala. Kebutuhan monitoring berubah seiring infrastruktur berkembang.
Penutup
Monitoring adalah mata dan telinga kamu di dunia infrastruktur. Tanpa itu, kamu buta terhadap apa yang terjadi di sistem yang kamu kelola.
Tidak perlu tools paling mahal atau paling canggih. Yang penting adalah visibilitas terhadap kesehatan sistem.
Mulai dengan yang simple. Uptime monitoring untuk endpoint penting. Metrics dasar untuk setiap server. Alert ke channel yang pasti dibaca.
Jangan tunggu sampai CEO bertanya “Kenapa website down?” baru berpikir tentang monitoring.
Karena saat itu, sudah terlambat.
Semoga pembahasan monitoring infrastruktur ini membantu kamu mengambil keputusan yang lebih tepat di lapangan.
Checklist Implementasi
- Uji langkah di lab terlebih dulu sebelum produksi.
- Dokumentasikan konfigurasi, versi, dan langkah rollback.
- Aktifkan monitoring + alert untuk komponen yang diubah.
- Audit akses dan terapkan prinsip least privilege.
Referensi Resmi
Butuh Bantuan?
Jika ingin implementasi aman di produksi, saya bisa bantu assessment, eksekusi, dan hardening.
Hubungi SayaTentang Penulis
Kamandanu Wijaya
IT Infrastructure & Network Administrator
Administrator infrastruktur & jaringan dengan pengalaman enterprise 14+ tahun, fokus stabilitas, keamanan, dan automasi.
Sertifikasi: Google IT Support, Cisco Networking Academy, DevOps.
Lihat ProfilButuh Solusi IT?
Tim DoWithSudo siap membantu setup server, VPS, dan sistem keamanan lo.
Hubungi Kami